
Despite a preference by some for the tactile charm of paper maps and reassuringly mundane spreadsheet software, the tools available to transport planners have come a long way in recent years. And yet while the advantages over these older, more time-consuming, and difficult-to-scale processes are many, newer, digital systems are not without their potential pitfalls.
Perhaps the most complicating of all possible issues that might arise out of systems built to exist in a wider software ecosystem is the failure to effectively interoperate. Interoperability, when implemented correctly, means different software systems working together seamlessly, allowing data and information to be easily exchanged and used by other applications. For transport planners, this empowers collaboration with stakeholders from different departments or even different organisations, without worrying about data silos or incompatible software systems. It enables them to easily share data and insights, leading to better decision-making and more efficient transportation planning.
In the context of collaborative transport planning, interoperability is crucial for several reasons:
-
Increased Efficiency: With interoperable software, planners can easily transfer data from one application to another, reducing the time and effort required to manually enter information, allowing for a more efficient and streamlined workflow.
-
Improved Data Analysis: Transport planners can easily combine data from different sources and analyse it in a single application, providing a comprehensive view of their transport networks. This helps to make informed decisions based on a comprehensive analysis of the data.
-
Enhanced Collaboration: This improves communication, helping planners share data and collaborate with stakeholders, while eliminating the risk of errors that can occur when manually transferring information.
Planners today might work with a host of complex file formats, some with extensive formalised specifications, e.g. GTFS, and others with no inherent semantic structure whatsoever, such as CSV files. Proprietary file formats complicate things further and many of the tools available (especially those online) for converting file formats are essentially black boxes, that give no real insight into how they work or the fidelity of their conversions.
Lost In Translation
And while poor interoperability is sometimes no more than an inconvenience, the potential for costly oversights is a lingering concern. History is littered with examples of technological mishaps resulting from mismatched file formats and poorly implemented interoperability. Minor miscalculations that have led to costly remediation efforts or in worst case scenarios, collapsed a project entirely. In 2007, NASA lost contact with its Mars Global Surveyor spacecraft after a software update caused a mismatch between two file formats: one that used imperial units and one that used metric units. This resulted in incorrect calculations of the spacecraft’s orientation and solar panel position. The spacecraft eventually ran out of power and stopped communicating with Earth. Bummer.
Back in the transport planning domain, there are numerous file formats to contend with on a daily basis. In certain cases, those formats may have optional elements or elements that are optional under certain conditions. GTFS datasets, for example, comprise six required, and seven optional files, and so are often of varying quality and completeness. This can limit the accurate visualisation and analysis of these feeds, and comparison with other, more complete feeds.
Similarly, geospatial dataset formats such as those in the GeoJSON format have presented issues for planners in the past by permitting alternative coordinate reference systems (CRSs) as part of its specification. This aspect of the GeoJSON format has since been removed, having ‘proven to have interoperability issues’. Despite this, and despite the acknowledgement that ‘in general, GeoJSON processing software is not expected to have access to coordinate reference system databases or to have network access to coordinate reference system transformation parameters” alternative CRSs can be used “where all involved parties have a prior arrangement”.
In reality, these sorts of specifications can be considered ‘best laid plans’ and such “prior arrangements” frequently do not occur. Furthermore, there is a growing expectation that the tools that we use to process this data should be intelligent enough to identify its format, transform or repair it if necessary and offer solutions for working with incomplete or incongruous data. And the majority of this processing should be done invisibly.
Perhaps there's a philosophical question here - can data ever be considered truly bad, or is it just misunderstood? Regardless, the trend for systems that can handle ‘bad’ data elegantly and without resorting to hysterical language (‘kernel panic’, ‘blue screen of death’, “fatal exception’) is unlikely to reverse.
We've talked about GTFS on this blog before, and visualising, analysing, creating and editing both GTFS and TransXChange files remains one of the most common uses of Podaris. In creating a system robust enough to ingest feeds of any quality, we have sought to balance convenience and transparency - allowing you to make the import process a one click affair, or, should you choose, to drill down into the details of your feeds and decide how they will be imported, and what should be done in the case of missing data.
Everything we've described so far has involved working with static files that it is assumed will be stored, transferred (often by email), imported, transformed, exported and then stored again. While Podaris accommodates this way of working, since its inception, it has been designed for a far more collaborative way of working. One in which projects are living documents, that never require saving, that can be edited by multiple people at the same time and which always remain synchronised between those viewing and editing them. Data within and outside of the platform can be further synchronised by use of Application Programming Interfaces (APIs), shown below.
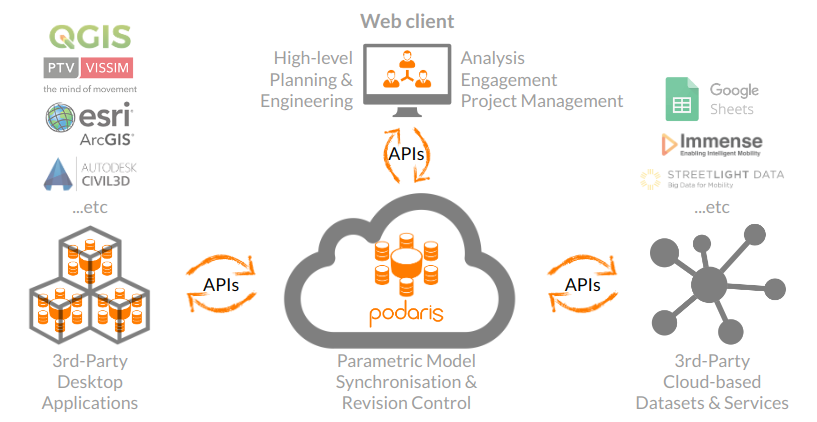
And interoperability within Podaris is not confined to playing well with other file formats. Where possible, projects can be connected with third-party applications through integrations, allowing your Podaris-based transport projects to leverage calculation tools within Google Sheets, for example.
This bidirectional syncing of data without the need to export and import with each change made is true interoperability, and opens the doors to a vast number of analysis capabilities beyond those included with Podaris. In the coming months we'll be announcing some very exciting features designed to unleash the capabilities of Podaris in ways that are limited only by your imagination.
Be the first to hear about them by subscribing to our newsletter below, or take a complete tour of Podaris today by scheduling a demo.